Samsung Research in Japan is part of a series about the people and innovations behind the democratization of mobile AI
As Samsung continues to pioneer premium mobile AI experiences, we visit Samsung Research centers around the world to learn how Galaxy AI is enabling more users to maximize their potential. Galaxy AI now supports 16 languages, so more people can expand their language capabilities, even when offline thanks to on-device translation in features such as Live Translate, Interpreter, Note Assist and Browsing Assist. But what does AI language development involve? Last time, we visited Poland to discover how European countries collaborate to accomplish their goal. This time, we’re in Japan to see how developers are constantly adapting to new scenarios and use cases.
Samsung R&D Institute Japan (SRJ) was established as an R&D center focused on hardware such as home appliances and displays. With the demand for AI innovation ramping up globally, SRJ in Yokohama has also been operating a software development lab to create Galaxy AI’s Live Translate, which automatically translates voice calls in real time, since the end of last year.
“Live Translate is particularly efficient for travel scenarios such as visitors to this year’s Olympic Games in Paris,” says Takayuki Akasako, the Head of Artificial Intelligence at SRJ. “We are currently developing a speech recognition program for people who are both sightseeing and watching the Paris Olympic Games; by training the speech recognition program to learn about the games and locations of stadiums for Paris 2024.”

Understanding Context in Voice Recognition
For those already using the translation features of Galaxy AI, such functionalities may seem very useful. But for developers who have made the features come to life, they know that being able to communicate while traveling abroad isn’t something that can be taken for granted.
One thing the team noted was that there are more homonyms in Japanese than some other languages. For instance, ‘chopsticks’ (Hashi,箸) and ‘bridge’ (Hashi,橋) are relatively easy to distinguish due to the difference in intonation, but words like ‘sightseeing’(Kankō,観光), ‘customs’(Kankō,慣行), ‘public’ (Kōkyō,公共) and ‘prosperity’ (Kōkyō,好況) must be judged based on the context.
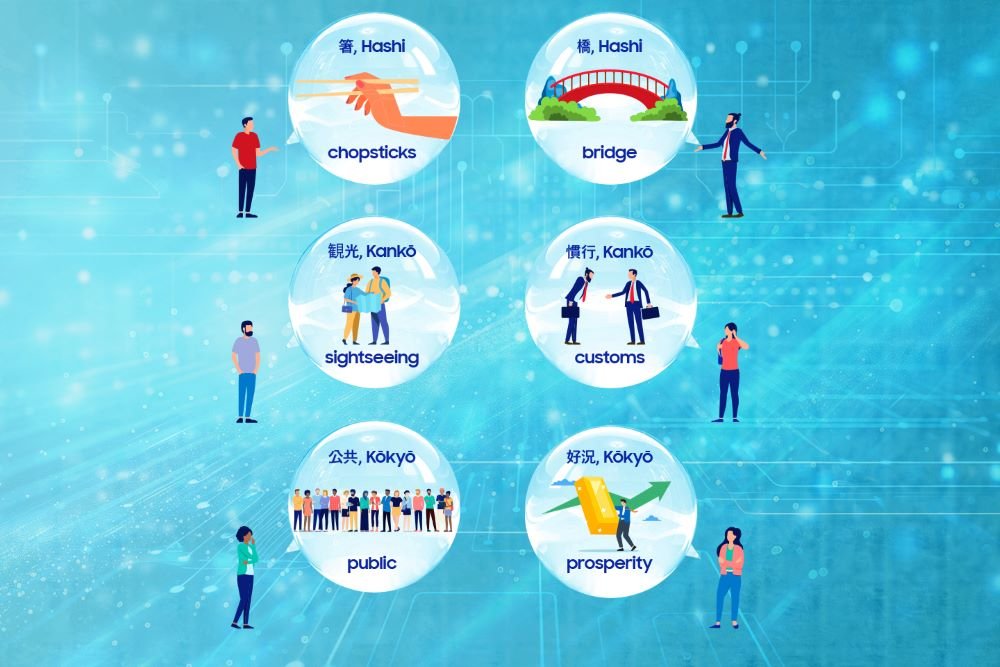
“Judgement becomes more difficult when the context is ambiguous, such as names of locale and people, proper nouns, dialects and numbers,” says Akasako. “So in order to improve the accuracy of speech recognition, a lot of data is needed.”
“We always look for ways to fine-tune the AI model for key events and moments in a timely manner,” continues Akasako. “With a lot of new combinations of place names and activities, it’s important that the context is still clear when people are using Galaxy AI.”

Challenges in Collecting Efficient Data
While recognizing the types of data needed is also important, collecting the data in and of itself is a challenge in its own right.
Previously, the SRJ team used human-recorded data to train the speech recognition engine for Live Translate, which didn’t result in sufficient data collection.
Samsung Gauss, the company’s Large Language Model (LLM), uses scripts to structure sentences with words or phrases that are relevant to each scenario. The data collected with Samsung Gauss is not only recorded by humans, but also generated by a speech synthesis text-to-speech (TTS) data, through which human resources do the final check on the quality. Using this method, the team has seen a dramatic improvement in data collection efficiency.
“Every time a problem is identified and solved, the accuracy of speech recognition improves significantly,” says Akasako. “Regardless of where people are, our goal is connecting people with each other, and the tools powered by Galaxy AI will ensure more fun and efficient communication.”
This article was first published at Source link . You can check them out for other stuffs